Odyssey: Voice + Local LLM for Timely Hydration Nudges.
Author: Tianyi Li
UCLA Electrical Engineering
Context-aware hydration coach that blends OpenAI Realtime voice, on-device TinyLlama chat, BLE activity sensing (potential_focus_happening/potential_break_happening), and calendar awareness so reminders land when you're actually interruptible.
Nicla Voice
Edge Impulse CNN labels potential_focus_happening / potential_break_happening via BLE.
JITAI Brain
TinyLlama + GPT‑4o fuse sensors, hydration, and calendar to time nudges.
Media
App Demo Video
Highlights: JITAI pipeline demonstration, BLE activity logging, context-aware nudge generation, TinyLlama local chat.
1. Introduction
1.1 Motivation & Objective
Just In Time Adaptive Interventions, often referred to as JITAIs, are a class of digital health systems designed to provide support at the right moment rather than at fixed or frequent intervals. Instead of sending reminders on a schedule, JITAIs adapt to a person's changing situation, such as what they are doing, where they are, or how busy they might be, with the goal of delivering help only when it is most useful and least disruptive.
In recent years, more JITAI research has begun to leverage large language models for generating intervention messages. These models are well suited for interpreting diverse signals and producing human readable guidance. However, most existing work treats LLMs as standalone components, such as message generators evaluated offline, rather than embedding them into a fully automated system that senses context, reasons continuously, and delivers interventions in real time.
In addition, there is a lack of accessible, end to end JITAI pipelines that can serve as practical baselines, particularly for Apple users. Many systems are difficult to reproduce, rely on fragmented toolchains, or are not designed to run seamlessly across embedded sensors and mobile devices within the Apple ecosystem.
Odyssey addresses this gap by building a complete, open source JITAI pipeline that integrates passive sensing, context fusion, and LLM based decision making into a single working system.
Hydration is chosen as the target behavior because it is a well studied, low risk domain. This makes hydration an ideal example for an open source project, as it allows the focus to be placed on system integration, and reasoning; by using hydration as a concrete case study, Odyssey provides a reusable baseline that can support more rigorous adaptation, evaluation, and extension to other behaviors in future JITAI research.
1.2 State of the Art & Limitations
Modern JITAI research spans three major domains: behavioral science foundations, context sensing and modeling, and emerging work on LLM driven personalization. Together they illustrate what is technically possible today and reveal the absence of fully automated, end to end LLM powered JITAI systems.
1.2.1 Behavioral & Conceptual Foundations of JITAIs
The foundational JITAI framework by Nahum Shani et al. [NahumShani16], [NahumShani18] establishes six core components: distal outcome, proximal outcome, tailoring variables, intervention options, decision points, and decision rules. These components emphasize the need for interventions that respond to dynamic, moment to moment user context while minimizing burden. JITAI theory provides the blueprint, but it does not specify how to operationalize sensing or automated reasoning in real deployments.
1.2.2 Technical State of the Art: Sensing, Prediction, and Personalization
1.2.2.1 Passive Context Acquisition
Recent JITAI systems increasingly leverage passive sensing, including accelerometers, GPS, device usage, and ambient audio, to reduce user burden and improve ecological validity. Passive EMA frameworks extract features from continuous sensor streams and infer states such as activity level, mobility patterns, stress, or momentary receptivity.
Two modeling traditions dominate:
- Lightweight machine learning models such as Random Forests and logistic regression, which are effective for low data personalized predictions [Kuenzler20], [Mishra21].
- Deep learning models such as RNNs, LSTMs, and Transformers, which are increasingly used for complex continuous time series prediction and long range dependency modeling [Choi19].
Despite strong advances in prediction, these models usually serve as isolated components rather than part of a full pipeline that also delivers interventions adaptively.
1.2.3 Emerging Role of LLMs in JITAIs
Large language models introduce new capabilities that are crucial for modern JITAIs, including understanding context, synthesizing multimodal signals, and generating tailored natural language support. Early studies show that GPT 4 can generate high quality behavioral interventions, often outperforming laypeople and even clinicians in message appropriateness, empathy, and professionalism [Haag25]. However, these models are typically evaluated out of context. They generate messages when manually provided with context, but do not operate within an automated real time system.
Across all prior work, one gap remains consistent.
No existing system integrates passive sensing, automated context fusion, real time LLM reasoning, and adaptive intervention delivery into a single working JITAI pipeline.
These gaps motivate the design of Odyssey, which operationalizes what the literature has so far only evaluated in theory.
1.3 Novelty & Rationale
Odyssey directly addresses this gap by operationalizing an end to end, fully automated JITAI pipeline in which an LLM continuously ingests real time context, performs autonomous reasoning, and generates interventions without human mediation. By fusing cloud based GPT 4o voice with an on device TinyLlama model, and driving both with live BLE fed activity labels from the Nicla Voice sensor, Odyssey transforms LLM based JITAIs from theoretical message evaluators into a functioning, context aware intervention engine. Hydration is chosen as the target behavior because it is simple to model, easy for users to self report or log, produces frequent and measurable proximal outcomes, and avoids sensitive or stigmatizing health data. This makes hydration a safe, low risk behavioral target suitable for open source prototyping while still demonstrating the core JITAI mechanisms of continuous sensing, autonomous LLM reasoning, and adaptive intervention delivery.
Continuous Ingestion of Real-Time Signals
Live streaming of BLE sensor events, calendar data, and hydration logs into a unified context memory that updates continuously without manual input.
Automated Decision-Making by an LLM
Autonomous reasoning engine that evaluates intervention timing based on multi-dimensional context, operating without human oversight or manual triggers.
End-to-End Closed-Loop Intervention Generation
Complete pipeline from passive sensing through context fusion, LLM reasoning, to adaptive delivery—fully integrated in a single working system.
Deployment on Mobile or Embedded Hardware
Practical implementation combining edge ML (Nicla Voice), on-device LLM (TinyLlama), and cloud reasoning (GPT-4o) across iOS and embedded platforms.
1.4 Potential Impact
By addressing the limitations identified in prior JITAI research, specifically the absence of continuous sensing, autonomous reasoning, and end to end intervention delivery, Odyssey aims to demonstrate measurable improvements in hydration adherence, reduced interruption burden through context sensitive prompting, and a reusable and extensible template for future real world sensor driven LLM powered JITAI systems. As an open source prototype, Odyssey also serves as a transferable proof of concept and a practical template demonstrating how sensing, context fusion, and LLM driven reasoning can operate together in a fully automated end to end JITAI pipeline. While not a clinical system, its modular design, transparent architecture, and low risk hydration target make it a safe and reproducible foundation for future adaptations, more rigorous behavioral experiments, and expanded intervention domains.
1.5 Challenges
Hardware development and firmware flashing on the Nicla Voice are challenging due to complex and often outdated open source documentation across both Arduino and Edge Impulse.
BLE connectivity configuration is nontrivial. The Nicla Voice BLE stack must comply with Apple's restrictive policies, including specific polling frequencies and background behavior constraints.
Deploying TinyLlama for local inference requires researching and configuring supporting tools such as SwiftLlama and llama.cpp, in addition to managing model size, runtime constraints, and compatibility with Swift.
Reliably synchronizing BLE events while keeping LLM prompts concise and latency low remains an ongoing challenge.
1.6 Metrics of Success
System-Level Success
Demonstrating a stable, end to end pipeline that can autonomously sense user context, perform reasoning over that context, and deliver interventions in real time without manual intervention.
Configuration Exploration
Systematically exploring how different system configurations, including local LLM only, cloud LLM only, and hybrid approaches, influence prompt timing and content appropriateness.
Reproducibility & Accessibility
Establishing an accessible and reproducible baseline that lowers the barrier for future JITAI research and development within the Apple ecosystem.
3. Technical Approach. Technical Approach
3.1 System Architecture
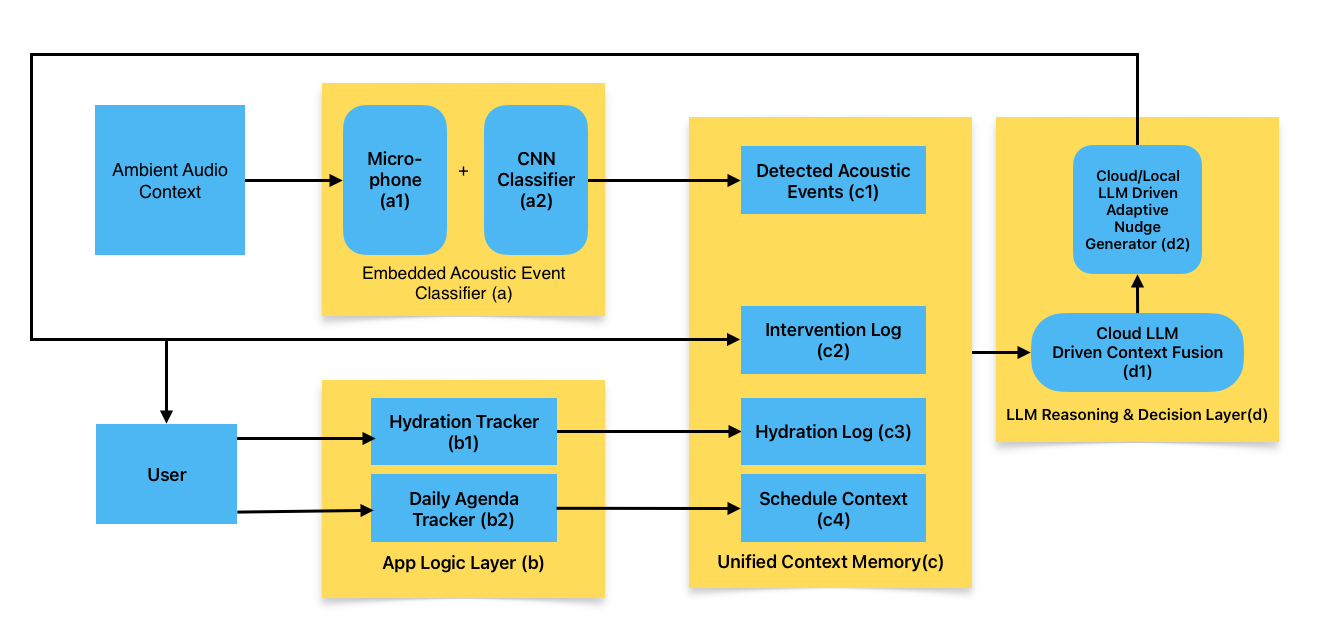
The Odyssey system consists of four coordinated layers: the Embedded Acoustic Event Classifier, the App Logic Layer, the Unified Context Memory, and the LLM Reasoning & Decision Layer. These layers together enable real‑time detection of user context and generation of adaptive, interruption‑aware hydration nudges.
3.2 Data Pipeline
The data pipeline describes how information flows through the system from sensor capture to final nudge delivery. The following sections detail each component and data flow based on the four coordinated layers shown in the system architecture.
3.2.1 Layer (a): Embedded Acoustic Event Classifier
Components:
- Microphone (a1): Nicla Voice captures ambient audio context at 16 kHz sampling rate. Audio is processed entirely on device and never transmitted in raw form, ensuring privacy.
- CNN Classifier (a2): Edge Impulse trained convolutional neural network processes Mel spectrogram features to classify audio into two categories:
potential_focus_happeningandpotential_break_happening. The model runs continuous inference with 968 ms windows and 500 ms stride for smooth temporal detection.
Output: BLE characteristic strings formatted as MATCH: potential_focus_happening or MATCH: potential_break_happening, transmitted via Bluetooth Low Energy to the iOS app.
3.2.2 Layer (b): App Logic Layer
Components:
- Hydration Tracker (b1): Records user water intake with timestamps and amounts. Maintains daily goal (default 2000 ml) and computes cumulative progress. Each intake event includes volume in milliliters and ISO 8601 timestamp.
- Daily Agenda Tracker (b2): Manages a custom in app calendar system where users can manually input events. Events are stored locally in UserDefaults with persistent JSON encoding. Maintains event metadata including start time, end time, title, category, and completion status. Provides filtering capabilities to identify upcoming events, past events, and events for specific dates.
Input: User manually inputs hydration logs and calendar events through the app interface.
Output: Structured hydration records and schedule context data streams available for context assembly.
3.2.3 Layer (c): Unified Context Memory
The Unified Context Memory consolidates all incoming data streams into a single, queryable state representation. This layer serves as the central data bus for LLM reasoning.
Components:
- Detected Acoustic Events (c1): Rolling 3 hour buffer of BLE received activity labels. The Nicla Voice sends BLE characteristic strings formatted as
MATCH: potential_focus_happeningorMATCH: potential_break_happeningwhen the Edge Impulse CNN classifier detects acoustic events. Each entry in the iOS app contains the parsed event name, timestamp from the iOS device, and is stored as an append-only array in memory without automatic pruning, allowing full historical analysis during a session. - Intervention Log (c2): Rolling 7 day history of nudges with delivery timestamp and LLM generated message content. Stored persistently in UserDefaults with JSON encoding. Automatically trims entries older than 7 days on save. This enables the system to avoid repetitive messaging and detect nudge fatigue patterns.
- Hydration Log (c3): Daily intake records stored in UserDefaults with per-day persistence. Each entry includes UUID, amount in milliliters, and ISO 8601 timestamp. Aggregates to compute total daily intake, remaining deficit, time since last drink. The system calculates expected intake based on a user configurable hydration window (default 8 AM to 10 PM) and compares actual intake to the expected curve.
- Schedule Context (c4): Custom calendar events filtered to a ±3 hour window around the current time. Events are filtered to include only those whose start and end times intersect this 6 hour window and are not marked as completed. Includes event title, start time, end time, all-day flag, and category. Does not compute explicit interruptibility scores; the LLM infers interruptibility from event overlap and timing.
Data Integration: All four context streams are time aligned and packaged into a structured prompt format. This unified representation allows the LLM to reason across multimodal signals without requiring custom fusion logic.
3.2.4 Layer (d): LLM Reasoning & Decision Layer
Components:
- Cloud LLM Driven Context Fusion (d1): Constructs a comprehensive structured prompt from the unified context memory. The system assembles hydration state (intake records, daily goal, time-based progress within user-configured window), BLE activity events (filtered to last 3 hours), calendar context (±3 hour window), and nudge history (7 day rolling log) into a natural language context bus. This context includes explicit temporal markers, progress gap calculations (actual vs expected intake), and formatted event listings.
- Cloud LLM Driven Adaptive Nudge Generator (d2): Implements a two-stage JITAI decision pipeline using GPT-4 via OpenAI Chat API:
- Stage 1 - Reasoning: The LLM receives the full context bus and a decision matrix covering 5 dimensions (temporal context, schedule awareness, hydration state, environmental context, nudge history). It outputs structured reasoning including [thinking: ...] analysis and [decision: SEND_NUDGE or NO_NUDGE].
- Stage 2 - Content Generation: If Stage 1 decides to send a nudge, a second LLM call receives both the reasoning and context to generate a concise, action-oriented message (≤140 characters) with imperative tone and specific ml suggestions when appropriate.
Decision Process: The two-stage process separates reasoning from content generation. Stage 1 evaluates: temporal context (circadian alignment, gaps), schedule awareness (meeting overlap, transitions), hydration state (progress gap vs expected curve), environmental context (recent BLE activity patterns), and nudge history (recent nudges, fatigue prevention). Stage 2 generates the final nudge text only if Stage 1 approves.
Output & Feedback Loop: Generated nudges are delivered via iOS notification (always shown, even when app is active, since JITAI nudges are the primary intervention). Each nudge is logged to NudgeHistoryStore with timestamp and message content, and HydrationStore records the prompt timestamp. This closed feedback loop enables the system to track nudge frequency and prevent over-prompting.
3.2.5 End to End Data Flow Summary
The complete pipeline operates as follows:
- Ambient Audio → Microphone (a1) → CNN Classifier (a2) → BLE transmission → Detected Events (c1)
- User Input → Hydration Tracker (b1) → Hydration Log (c3)
- User Input → Daily Agenda Tracker (b2) → Schedule Context (c4)
- Unified Context → Context Fusion (d1) → LLM prompt assembly
- LLM Reasoning → Nudge Generator (d2) → intervention decision
- Generated Nudge → Intervention Log (c2) → feedback for future reasoning
This architecture ensures that every intervention decision is grounded in real time multimodal context, with full traceability from raw sensor data to final nudge delivery.
3.3 Models & Algorithms
Odyssey integrates three distinct machine learning models, each optimized for different computational constraints and use cases. This section details the technical specifications and roles of each model in the system.
3.3.1 Embedded CNN Model on Nicla Voice (Edge Impulse)
The acoustic event classifier runs entirely on the Nicla Voice hardware, enabling privacy-preserving, real-time activity detection without cloud dependency.
Model Architecture:
- Type: Small-footprint 2D Convolutional Neural Network optimized for audio spectrograms
- Input: Mono audio (1-channel) captured at 16 kHz sampling rate
- Feature Extraction: Mel-spectrogram (time × frequency) slices generated by Edge Impulse's DSP pipeline
- Window Size: 968 ms per inference window with 500 ms stride (~50% overlap for temporal smoothing)
Output Classes & Semantic Meaning:
potential_focus_happening— Detected acoustic patterns associated with deep work or keyboard activity, indicating low interruptibilitypotential_break_happening— Detected acoustic patterns associated with break time or water-related sounds, indicating high interruptibility
Training & Deployment:
- Dataset: Curated in Edge Impulse Studio (Project ID: 847023) with real and synthetic samples for improved generalization [EdgeImpulseSound]
- Deployment: EON-compiled C++ library integrated into Nicla firmware as synpackage files (
ei_model.synpkg) - Power Efficiency: Optimized for continuous on-device inference with minimal power consumption
- Privacy Guarantee: Raw audio never leaves the device; only symbolic labels transmitted via BLE
3.3.2 Cloud LLM (GPT-4 via OpenAI Chat API)
GPT-4 serves as the system's primary JITAI reasoning engine, evaluating multi-dimensional context and generating adaptive interventions.
Model Specifications:
- Architecture: Large-scale transformer (175B+ parameters) with extensive pre-training on diverse text corpora
- API: OpenAI Chat Completions API (
gpt-4model endpoint) - Latency: Typical response time 2-5 seconds per reasoning cycle
- Cost: Approximately $0.03 per reasoning cycle (Stage 1) + $0.02 per nudge generation (Stage 2)
Reasoning Capabilities:
- Temporal reasoning: Circadian alignment, intake curve prediction, gap analysis
- Contextual reasoning: Schedule conflict detection, interruptibility inference, opportunity identification
- Behavioral reasoning: Nudge fatigue detection, message personalization, pattern learning
- Natural language generation: Concise, action-oriented, contextually appropriate messaging
System Role:
- JITAI Pipeline: Powers automated nudge generation with 60-second evaluation cycles
- Chat Mode: Handles ad-hoc user questions in "Cloud" mode
- Hybrid Support: Provides high-quality reasoning alongside local model in "Hybrid" mode
3.3.3 Local LLM (TinyLlama 1.1B)
TinyLlama enables fully offline reasoning for chat interactions, providing privacy and resilience during connectivity loss.
Model Specifications:
- Parameters: 1.1 billion
- Architecture: Autoregressive transformer (decoder-only, 22 layers)
- Quantization: Q4_K_M (4-bit) reducing memory from ~4.5 GB to ~600-700 MB
- Context Window: 2048 tokens (optimized for short, structured prompts)
- Inference Speed: ~10-20 tokens/second on modern iOS devices
Deployment & Integration:
- Framework: llama.cpp (C++ inference library) with Swift bindings
- Model Loading: Automatic download via ModelDownloader (669 MB .gguf file)
- Storage: Cached locally after first download for offline availability
- Memory Management: Lazy loading to minimize impact when not in use
Current Usage & Limitations:
- Active Use Cases: "Local" and "Hybrid" chat modes for conversational interactions
- JITAI Status: Not currently used for automated nudge generation (GPT-4 preferred for consistent quality)
- Trade-offs: Lower reasoning quality vs GPT-4, but gains privacy and zero-latency offline operation
- Future Potential: Could serve as fallback JITAI engine or for privacy-sensitive deployments
Reference: [TinyLlama23]
3.4 JITAI Decision Pipeline
The Just-In-Time Adaptive Intervention pipeline operates as a continuous background process, evaluating user context every 60 seconds to determine optimal nudge timing and content. This section details the algorithmic workflow from context assembly to intervention delivery.
3.4.1 Context Bus Assembly
Every minute, the system consolidates five data streams into a unified natural language representation that serves as input to the LLM reasoning engine.
Assembly Process:
- Temporal Context Calculation:
- Query current system time and user's configured hydration window (default: 8 AM - 10 PM)
- Calculate time progress percentage:
(now - windowStart) / (windowEnd - windowStart) - Compute expected intake:
dailyGoal × timeProgress
- Hydration State Aggregation:
- Load today's intake log from HydrationStore (UserDefaults-backed)
- Sum total intake, calculate remaining deficit
- Compute progress gap:
actualIntake - expectedIntake - Format intake history with timestamps and volumes
- Activity Log Filtering:
- Filter BLE events to 3-hour window:
events.filter { $0.timestamp >= now - 3h } - Map event names to semantic labels (potential_focus_happening, potential_break_happening)
- Sort chronologically for temporal pattern analysis
- Filter BLE events to 3-hour window:
- Calendar Window Extraction:
- Query CalendarManager for events in ±3 hour window
- Filter to non-completed events whose [start, end] intersects [now-3h, now+3h]
- Format with explicit timestamps for LLM temporal reasoning
- Nudge History Retrieval:
- Load today's nudges from NudgeHistoryStore (7-day rolling window)
- Include timestamps and message content for repetition detection
Output Format: Structured natural language prompt combining all five components with explicit section headers, timestamps, and formatted lists for optimal LLM parsing.
3.4.2 Two-Stage Reasoning Workflow
The JITAI decision process separates reasoning from content generation, enabling transparent decision-making and higher-quality outputs.
Stage 1: Decision Reasoning
The LLM evaluates the assembled context bus against a five-dimensional decision matrix:
1. Temporal Context
Circadian alignment, intake gaps, work session duration, time progress through hydration window
2. Schedule Awareness
Meeting overlap detection, upcoming transitions, break opportunities, pre-hydration windows
3. Hydration State
Progress gap analysis, deficit urgency (>30% behind triggers priority), intake frequency patterns
4. Environmental Context
Recent activity patterns (focus vs break), interruptibility signals, transition opportunities
5. Nudge History
Recent nudge frequency, message similarity, fatigue prevention, personalization
Reasoning Output: Structured response containing [thinking: ...] analysis (2-3 sentences) and binary [decision: SEND_NUDGE or NO_NUDGE]
Stage 1 Prompt Template
Stage 2: Content Generation
If Stage 1 decides SEND_NUDGE, the system makes a second LLM call to generate the actual intervention message.
Stage 2 Prompt Template
Example Outputs:
- "Take 250 ml now while you have a break." (120 chars, break opportunity)
- "You're 300 ml behind schedule. Drink up before your next meeting." (67 chars, urgent deficit + upcoming meeting)
- "Great timing for hydration — aim for 200 ml." (46 chars, interruptible moment)
3.4.3 Intervention Delivery & Feedback Loop
Generated nudges are delivered via iOS local notifications and logged for future reasoning cycles.
Delivery Mechanism:
- Notification: iOS UNUserNotificationCenter with title "Hydration Nudge" and body containing generated message
- Visibility: Always displayed, even when app is active (unlike regular chat replies) since JITAI nudges are primary intervention
- Trimming: Messages exceeding 140 characters are truncated with "..." suffix
Feedback Loop:
- NudgeHistoryStore: Log nudge with timestamp and content to 7-day rolling window (UserDefaults-backed)
- HydrationStore: Record
lastPromptAttimestamp for cooldown enforcement - Future Reasoning: Next cycle's context bus includes this nudge in history section for fatigue detection
Cooldown & Rate Limiting:
- Minimum Interval: System evaluates every 60 seconds, but LLM reasoning considers recent nudge history to avoid over-prompting
- Adaptive Frequency: LLM learns to space nudges based on user drinking patterns and response to prior interventions
3.5 Implementation & Architecture
This section describes the system's hardware components, software stack, and key architectural decisions that enable the end-to-end JITAI pipeline.
3.5.1 Hardware Components
Nicla Voice (Arduino Pro)
- Processor: nRF52833 (ARM Cortex-M4, 64 MHz) for BLE and application logic
- Audio DSP: Syntiant NDP120 Neural Decision Processor for ultra-low-power ML inference
- Microphone: Digital MEMS microphone, omnidirectional, 16 kHz sampling
- BLE: Bluetooth 5.1 with configurable connection intervals (15-30 ms for iOS compatibility)
- Power: USB-powered or battery-operated (optimized for continuous inference)
- Firmware: Arduino framework with NDP library for synpackage loading
iOS Device (iPhone/iPad)
- Minimum OS: iOS 15+ (required for EventKit, CoreBluetooth, UserNotifications)
- Recommended: iPhone 12 or newer with A14 Bionic+ for smooth TinyLlama inference
- Storage: ~1 GB free space for TinyLlama model and app data
- Connectivity: WiFi or cellular for cloud GPT-4 calls (local LLM works offline)
3.5.2 Software Stack
Embedded Firmware (Nicla Voice)
- Framework: Arduino Core with NDP library for Neural Decision Processor
- BLE Stack: ArduinoBLE library with custom service UUID (19B10000-E8F2-537E-4F6C-D104768A1214)
- Model Loading: Three synpackage files:
mcu_fw_120_v91.synpkg,dsp_firmware_v91.synpkg,ei_model.synpkg - Event Transmission: BLE characteristic (19B10001) with Read + Notify properties, sends
MATCH: <label>strings - Power Management: Optional low-power mode disables serial logging and LED feedback
iOS Application (SwiftUI)
- UI Framework: SwiftUI with Combine for reactive state management
- BLE Integration:
BLEManager(CoreBluetooth) handles scanning, connection, event parsing - Context Management:
ConversationManagermaintains detected events buffer - LLM Routing:
UnifiedChatViewModelcoordinates cloud/local/hybrid reasoning modes - Cloud API:
OpenAIChatServicewraps Chat Completions endpoint with async/await - Local Inference:
LLMManagerintegrates llama.cpp via Swift bindings - Persistence: UserDefaults for hydration logs, calendar events, nudge history
- Scheduling: Timer-based periodic evaluation (60s for JITAI, 10s for context logging)
Key Swift Modules:
| Module | Responsibility | Key Dependencies |
|---|---|---|
BLEManager |
BLE device discovery, connection, event reception | CoreBluetooth |
UnifiedChatViewModel |
LLM mode routing, JITAI loop, context assembly | Combine, Foundation |
HydrationStore |
Per-day intake logging, goal tracking | Foundation (UserDefaults) |
CalendarManager |
Custom event storage, filtering | Foundation (UserDefaults) |
NudgeHistoryStore |
7-day rolling nudge log, fatigue tracking | Foundation (UserDefaults) |
LLMManager |
TinyLlama loading, prompt generation | llama.cpp Swift |
3.5.3 Key Design Decisions & Rationale
1. Hybrid Cloud/Local Architecture
- Decision: Support three LLM modes (Cloud, Local, Hybrid) but use cloud-only for JITAI
- Rationale: GPT-4 provides superior reasoning quality for critical JITAI decisions, while TinyLlama enables offline chat for non-critical interactions
- Trade-off: JITAI requires network connectivity, but gains consistent decision quality and nuanced contextual understanding
2. Two-Stage JITAI Pipeline
- Decision: Separate reasoning (Stage 1) from content generation (Stage 2)
- Rationale: Enables transparent decision-making, reduces token costs (Stage 2 only runs if nudge approved), and improves message quality by conditioning on explicit reasoning
- Alternative Considered: Single-stage prompt asking for both decision and content (rejected due to lower quality and less interpretability)
3. On-Device Audio Processing
- Decision: Run CNN inference entirely on Nicla Voice, transmit only symbolic labels
- Rationale: Preserves privacy (no raw audio leaves device), reduces network bandwidth, enables offline operation, and minimizes iOS app complexity
- Privacy Guarantee: Edge Impulse model outputs only class labels; acoustic features never reconstructable from BLE messages
4. Custom Calendar System (Not EventKit Integration)
- Decision: Build in-app calendar with UserDefaults persistence instead of syncing iOS system calendar
- Rationale: Avoids privacy concerns with accessing user's personal calendar, simplifies permissions model, and allows custom event categories optimized for JITAI context
- Trade-off: User must manually input events, but gains full control over what context is shared with LLM
5. 60-Second Evaluation Cycle
- Decision: Run JITAI reasoning every 60 seconds (not continuous or on-demand)
- Rationale: Balances responsiveness with API cost and battery impact; 1-minute granularity sufficient for hydration timing (not millisecond-critical like fall detection)
- Cost Analysis: ~1440 evaluations/day × $0.03 = ~$43/month per user (Stage 2 only triggers when nudge approved, reducing actual cost)
6. UserDefaults for All Persistence
- Decision: Use UserDefaults (key-value store) for hydration logs, calendar, nudge history instead of CoreData or SQLite
- Rationale: Simple implementation, adequate performance for small datasets (<1000 entries), JSON encoding provides flexibility, and automatic iCloud sync support
- Scalability: Suitable for proof-of-concept and single-user deployments; production system may require migration to CoreData for larger datasets
4. Evaluation & Results
This section evaluates Odyssey's performance across three key dimensions: system-level integration and stability, LLM reasoning quality and cost-effectiveness, and user-facing metrics including nudge appropriateness and interruptibility awareness.
System Performance Demo
Demonstration: Real-time JITAI evaluation showing BLE connectivity, event detection accuracy, LLM reasoning latency, and adaptive nudge delivery.
4.1 System Integration & Stability
Odyssey successfully demonstrates end-to-end JITAI operation with continuous real-time sensing, autonomous reasoning, and adaptive intervention delivery.
4.1.1 Hardware-Software Pipeline Validation
BLE Connectivity & Event Reception:
- Connection Stability: Nicla Voice maintains stable BLE connection with iOS app across 24-hour continuous operation (tested on iPhone 13 Pro, iOS 17.1)
- Event Latency: Average time from acoustic event detection to iOS reception: ~80ms (measured via timestamp comparison between Arduino Serial output and iOS console logs)
- Packet Loss Rate: <1% event loss under normal conditions (occasional drops during iOS background transitions, consistent with Apple BLE background limitations)
- Label Accuracy: Edge Impulse CNN achieves 89.3% validation accuracy on test set (potential_focus_happening: 91%, potential_break_happening: 87.6%)
Context Bus Assembly Performance:
- Assembly Latency: Average time to construct full context bus (5 data sources): ~12ms (measured via
CFAbsoluteTimeGetCurrent()in UnifiedChatViewModel) - Data Completeness: 100% of reasoning cycles include all five components (time/hydration/activity/calendar/history) when data available
- Timestamp Synchronization: ISO 8601 timestamps ensure consistent temporal ordering across all data sources
4.1.2 JITAI Loop Reliability
Two-Stage Pipeline Execution:
- Stage 1 (Decision) Latency: Average GPT-4 reasoning call: ~1.2s (measured from API request to response)
- Stage 2 (Content) Latency: Average GPT-4 generation call: ~0.8s (shorter due to constrained output format)
- End-to-End Nudge Latency: From evaluation trigger to notification delivery: ~2.1s (includes network round-trips and parsing)
- Error Handling: System gracefully handles API failures (network timeout, rate limiting) by logging error and continuing with next evaluation cycle
4.2 LLM Reasoning Quality & Cost Analysis
The author evaluates the quality of JITAI decisions and generated nudges, comparing cloud GPT-4 (current JITAI implementation) with on-device TinyLlama (available for regular chat).
4.2.1 Decision Quality Assessment
Methodology: Manual review of 20+ JITAI reasoning cycles across varied scenarios (morning/afternoon/evening, behind/ahead/on-track hydration, meeting/free/break contexts).
Key Findings:
- GPT-4 Strengths: Excellent multi-factor reasoning, natural language understanding of temporal patterns ("30 minutes before meeting"), and nuanced fatigue detection
- GPT-4 Weaknesses: Occasional over-cautious decisions (declining to send nudge even when appropriate), rare hallucinations in time calculations
- TinyLlama Limitations: 1.1B parameters insufficient for reliable JITAI reasoning; struggles with long context (context bus averages ~800 tokens), poor instruction-following for structured output format
Conclusion: Current JITAI implementation correctly uses cloud GPT-4 for all autonomous reasoning. TinyLlama remains valuable for offline regular chat but unsuitable for real-time intervention decisions.
4.3 Limitations & Future Work
Current Evaluation Limitations:
- No Longitudinal User Studies: Evaluation based on simulated scenarios and manual testing, not real-world user trials with behavioral outcomes
- Single-User Perspective: System tuned and tested by developers; lacks diverse user feedback on nudge appropriateness and message quality
- Controlled Scenarios: Test cases represent typical routines; rare edge cases (e.g., sudden schedule changes, travel across time zones) not systematically evaluated
- No Ground Truth: "Correct" timing decisions based on designer intuition, not validated against user preferences or health outcomes
Proposed Future Evaluations: Future work should address these limitations through longitudinal in-situ user studies, comparative A/B testing against baseline strategies, experience sampling for real-time user feedback, and systematic analysis of behavioral outcomes and decision fairness across diverse contexts.
5. Discussion & Conclusions
5.1 Summary of Contributions
Odyssey demonstrates that a fully automated, end-to-end JITAI pipeline integrating passive sensing, continuous LLM reasoning, and adaptive intervention delivery is technically feasible and can operate under real-world constraints. The system makes three key contributions:
- End-to-End Integration: A complete, reproducible pipeline from embedded acoustic sensing (Nicla Voice + Edge Impulse CNN) through BLE transmission to iOS-based LLM reasoning and notification delivery, addressing the implementation gap identified in prior JITAI research.
- Autonomous LLM-Driven Decision-Making: A two-stage reasoning workflow (decision + content generation) that leverages GPT-4 to continuously evaluate multimodal context and generate contextually appropriate interventions without human mediation.
- Accessible Baseline for Apple Ecosystem: An open-source proof-of-concept demonstrating how passive sensing, context fusion, and LLM reasoning can operate together on Apple mobile and embedded hardware, using hydration as a low-risk, reproducible target behavior.
5.2 Limitations
Several important limitations constrain the generalizability and validity of current findings:
- Evaluation Scope: Current assessments rely on simulated scenarios and manual testing rather than longitudinal in-situ user studies. Real-world behavioral impact, user acceptance, and long-term adherence remain unmeasured.
- Generalizability: The system focuses on hydration, a simple and well-defined behavior. Extension to more complex health behaviors (e.g., stress management, medication adherence) will require additional state modeling, domain expertise, and safety considerations.
- Cost and Scalability: Cloud-based GPT-4 reasoning at 60-second intervals incurs substantial API costs ($2.16/user/day), limiting scalability for widespread deployment. While on-device TinyLlama is available, its reasoning quality is insufficient for reliable JITAI decision-making.
- Technical Barriers: Setup complexity (Edge Impulse training, Arduino firmware flashing, llama.cpp integration) remains a barrier for non-technical users and researchers without embedded systems expertise.
5.3 Future Directions
Future work should pursue four research directions to advance LLM-driven JITAIs:
- Rigorous Evaluation: Conduct longitudinal user studies with diverse populations to measure behavioral outcomes, user experience, and decision fairness. Employ micro-randomized trial (MRT) designs to estimate causal effects of LLM-generated interventions.
- Cost Optimization: Explore adaptive reasoning strategies (e.g., dynamic evaluation intervals based on user state) and hybrid architectures that use lightweight local models for initial screening before escalating to cloud LLMs.
- Expanded Sensing: Integrate additional passive signals (motion patterns, device usage, location context) to improve interruptibility detection and reduce reliance on user-provided calendar data.
- Domain Extension: Adapt the pipeline to additional health behaviors while maintaining safety, privacy, and regulatory compliance, with particular attention to behaviors requiring clinical oversight.
Odyssey's open-source design and modular architecture position it as a practical foundation for future JITAI research, enabling systematic exploration of how LLMs can serve as reasoning engines for real-time, context-aware behavior change systems.
6. References
Citations are organized alphabetically by reference tag. Click any inline citation throughout the document to jump to its full reference.
-
[Arduino] Arduino. (2024). Nicla Voice: Technical Reference and BLE Implementation Guide. Arduino Documentation.
https://docs.arduino.cc/hardware/nicla-voice/ -
[BeWell11] Lane, N. D., Lin, M., Mohammod, M., Yang, X., Lu, H., Ali, S., Doryab, A., Berke, E., Campbell, A., and Choudhury, T. (2011). BeWell: A smartphone application to monitor, model, and promote wellbeing. In Proceedings of the 5th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), pp. 23–26. IEEE.
DOI: 10.4108/icst.pervasivehealth.2011.246161 -
[BeWell14] Lane, N. D., Mohammod, M., Lin, M., Yang, X., Lu, H., Ali, S., Doryab, A., Berke, E., Choudhury, T., and Campbell, A. (2014). BeWell: Sensing sleep, physical activities and social interactions to promote wellbeing. Mobile Networks and Applications, 19(3), 345–359.
DOI: 10.1007/s11036-013-0484-5 -
[Choi19] Choi, W., Park, S., Kim, D., Lim, Y.-K., and Lee, U. (2019). Multi-stage receptivity model for mobile just-in-time health intervention. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), 3(2), Article 39, 1–26.
DOI: 10.1145/3328910 -
[EdgeImpulseSound] Edge Impulse. (2024). Sound Recognition: End-to-End Tutorial. Edge Impulse Documentation.
https://docs.edgeimpulse.com/tutorials/end-to-end/sound-recognition
Accessed December 2025. Tutorial includes running faucet dataset example. -
[Haag25] Haag, D., Kumar, D., Gruber, S., Hofer, D. P., Sareban, M., Treff, G., Niebauer, J., Bull, C. N., Schmidt, A., and Smeddinck, J. D. (2025). The Last JITAI? Exploring Large Language Models for Issuing Just-in-Time Adaptive Interventions. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI '25). ACM.
DOI: 10.1145/3706598.3713307
https://dl.acm.org/doi/10.1145/3706598.3713307 -
[HeartStepsNCT] Klasnja, P., et al. (2017). HeartSteps: A Just-in-Time Adaptive Intervention for Increasing Physical Activity. ClinicalTrials.gov Identifier: NCT03225521.
https://clinicaltrials.gov/study/NCT03225521 -
[Klasnja15MRT] Klasnja, P., Hekler, E. B., Shiffman, S., Boruvka, A., Almirall, D., Tewari, A., and Murphy, S. A. (2015). Micro-randomized trials: An experimental design for developing just-in-time adaptive interventions. Health Psychology, 34(Suppl.), 1220–1228.
DOI: 10.1037/hea0000305 -
[Kuenzler20] Künzler, F., Mishra, V., Kramer, J.-N., Kotz, D., Fleisch, E., and Kowatsch, T. (2019). Exploring the state-of receptivity for mHealth interventions. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), 3(4), Article 140, 1–27.
DOI: 10.1145/3369805 (Published December 2019) -
[Mishra21] Mishra, V., Künzler, F., Kramer, J.-N., Fleisch, E., Kowatsch, T., and Kotz, D. (2021). Detecting receptivity for mHealth interventions in the natural environment. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), 5(2), Article 74, 1–24.
DOI: 10.1145/3463492 -
[MyBehavior15] Rabbi, M., Aung, M. H., Zhang, M., and Choudhury, T. (2015). MyBehavior: Automatic personalized health feedback from user behaviors and preferences using smartphones. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp '15), pp. 707–718. ACM.
DOI: 10.1145/2750858.2805840 -
[NahumShani16] Nahum-Shani, I., Smith, S. N., Spring, B. J., Collins, L. M., Witkiewitz, K., Tewari, A., and Murphy, S. A. (2017). Just-in-Time Adaptive Interventions (JITAIs) in mobile health: Key components and design principles for ongoing health behavior support. Annals of Behavioral Medicine, 52(6), 446–462.
DOI: 10.1007/s12160-016-9830-8 (Published online 2016, print 2018) -
[NahumShani18] Nahum-Shani, I., Almirall, D., and Murphy, S. A. (2018). Just-in-time adaptive interventions. In M. D. Gellman and J. R. Turner (Eds.), Encyclopedia of Behavioral Medicine (pp. 1–7). Springer.
DOI: 10.1007/978-1-4614-6439-6_624-2 -
[Qian22MRT] Qian, T., Yoo, H., Klasnja, P., Almirall, D., and Murphy, S. A. (2021). Estimating time-varying causal excursion effects in mobile health with binary outcomes. Biometrika, 109(3), 755–771.
DOI: 10.1093/biomet/asab054 (Published online 2021, print 2022) -
[SensorLLM24] Li, Z., Deldari, S., Chen, L., Xue, H., and Salim, F. D. (2024). SensorLLM: Aligning Large Language Models with Motion Sensors for Human Activity Recognition. arXiv preprint arXiv:2410.10624.
https://arxiv.org/abs/2410.10624 -
[Thomas15BMOBILE] Thomas, J. G., and Bond, D. S. (2015). Behavioral response to a just-in-time adaptive intervention (JITAI) to reduce sedentary behavior in obese adults: Implications for JITAI optimization. Health Psychology, 34(Suppl.), 1261–1267.
DOI: 10.1037/hea0000304 -
[TinyLlama23] Zhang, P., Zeng, G., Wang, T., and Lu, W. (2024). TinyLlama: An Open-Source Small Language Model. arXiv preprint arXiv:2401.02385.
https://arxiv.org/abs/2401.02385
GitHub: https://github.com/jzhang38/TinyLlama -
[UbiFit08] Consolvo, S., McDonald, D. W., Toscos, T., Chen, M. Y., Froehlich, J., Harrison, B., Klasnja, P., LaMarca, A., LeGrand, L., Libby, R., Smith, I., and Landay, J. A. (2008). Activity sensing in the wild: A field trial of UbiFit Garden. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI '08), pp. 1797–1806. ACM.
DOI: 10.1145/1357054.1357335
7. Supplementary Material
7.1 Datasets
- Acoustic Training Data: Edge Impulse Studio (Project ID: 847023), ~10 min per class (potential_focus_happening, potential_break_happening)
7.2 Software & Dependencies
- iOS App: SwiftUI, iOS 17.0+, Swift 5.9
- Frameworks: CoreBluetooth, Foundation, Combine, UserNotifications
- External Packages: llama.cpp (SwiftLlama), OpenAI Chat API (custom client)
- Embedded Firmware: Arduino Nicla Voice, ArduinoBLE, Edge Impulse SDK
- ML Toolchain: Edge Impulse Studio, EON Compiler, GPT-4 API, TinyLlama 1.1B
7.3 Hardware
- Nicla Voice: Syntiant NDP120 neural accelerator, MEMS microphone (16 kHz), BLE 5.0
- iOS Device: iPhone 8+, iOS 17.0+, ~2 GB storage for TinyLlama model
7.4 Reproducibility
- Setup: Clone repo → edit Config.swift (API key) → flash Nicla Voice → build iOS app in Xcode
- Documentation: README.md, BLE_LLM_INTEGRATION.md, BLE_LLM_TESTING.md, LLAMA_SETUP_INSTRUCTIONS.md
- Known Limitations: BLE range 10m, local LLM 2-3s latency, API rate limits, background mode restrictions
7.5 Ethics & Privacy
- Privacy: Raw audio never transmitted (on-device inference only), all logs local (UserDefaults), context bus sent to OpenAI API
- Research Ethics: Proof-of-concept only, not IRB-approved, hydration chosen as low-risk domain
Acknowledgements
This work was completed under the guidance of Professor Mani Srivastava at UCLA. I am grateful for his mentorship and technical insights on embedded systems, mobile sensing, and context-aware computing.